Lable Distribution for Multimodal Machine Learning
条评论导读
多模态机器学习致力于通过多源数据来了解世界,如图像、语音和文本等。相比于单模态,多模态数据包含更多的信息,且模态之间具有互补性,因此多模态机器学习模型往往表现出比单模态更好的性能。然而,如何有效进行多模态融合,挖掘其中深层的特征表达,始终是多模态机器学习的重难点。区别于以往的多模态融合方法,本文考虑边信息引导多模态融合。提出多模态标记分布学习框架,利用边信息恢复出多模态标记分布,表示每个模态在描述示例时所占比例,然后采用多模态标记分布指导多模态融合,从而更准确的获取融合特征。针对不同的时序数据,本文进一步提出两个多模态标记分布学习算法,并分别应用于多模态情感识别与疾病诊断任务。实验结果正式了该算法优于现有先进算法。
多模态标记分布学习
区别于以往的多模态机器学习算法仅考虑各个模态特征,本文认为多模态融合会受到环境影响,如图1所示,当视频处于昏暗的环境中,我们会更关注于音频与字幕,而当视频处于嘈杂且没有字幕的时候,我们会更关注于图像来分析视频的内容。因此,本文提出利用边信息恢复出多模态标记分布,用于表示各个模态在环境影响下对示例的描述程度,并用多模态标记分布指导多模态融合,从而获得更准确的融合特征。由于真实世界数据中,缺少多模态标记分布的确切标注,因此,我们提出了一个端到端的多模态标记分布学习框架,利用任务的监督信号,通过反馈学习来获得多模态标记分布。
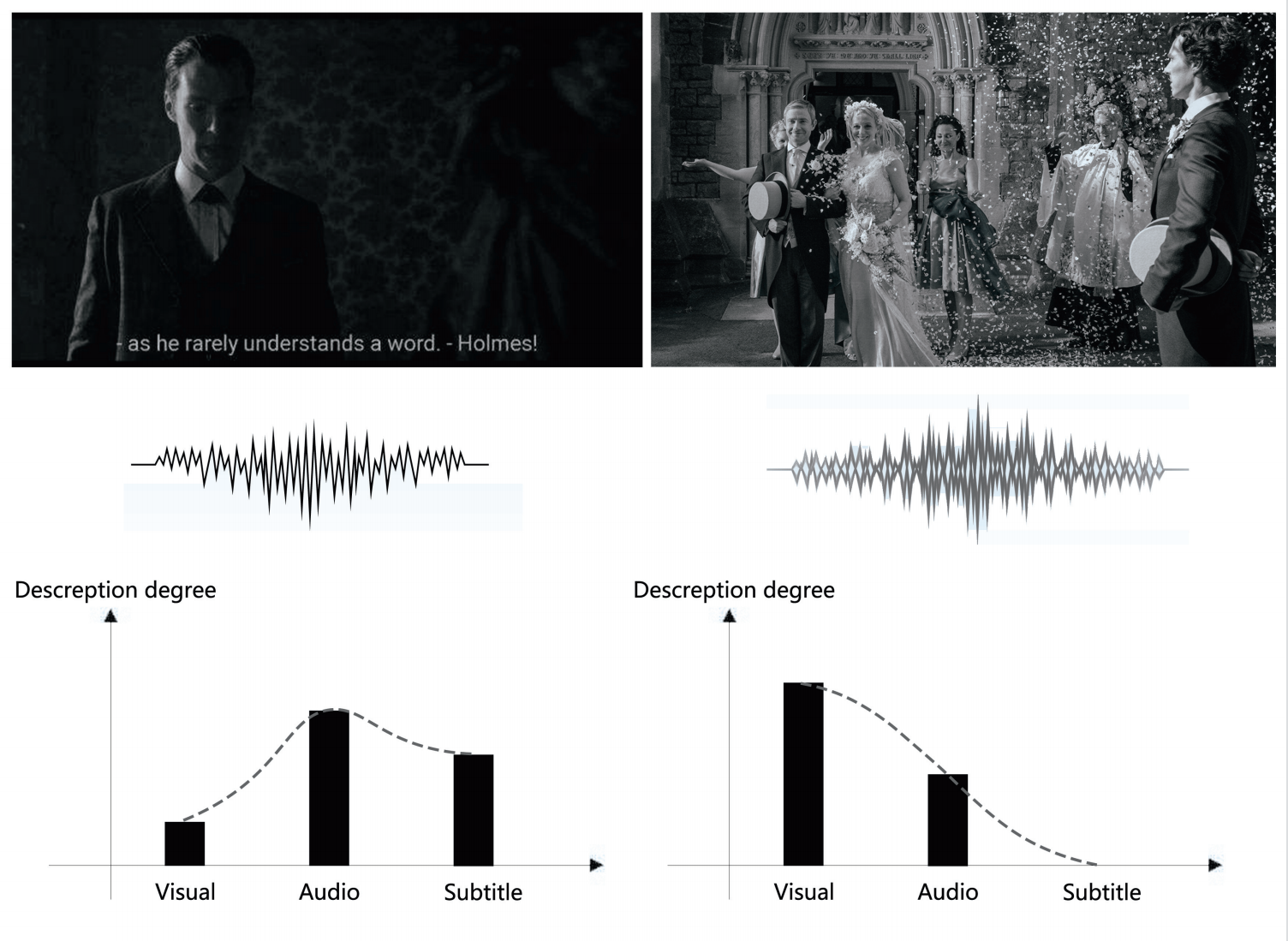 。在不同环境下,各个模态在描述示例时的比重会发生变化。
。在不同环境下,各个模态在描述示例时的比重会发生变化。
定义 为输入空间,包括边信息(维)与 个模态特征(用 表示第 个模态维度)。用 表示标记空间,共 个类。给定训练集 ,其中 为特征向量,包括边信息 与模态特征 , 为相应标记,为训练集数量。则多模态标记分布学习的任务为学习一个预测模型: 。
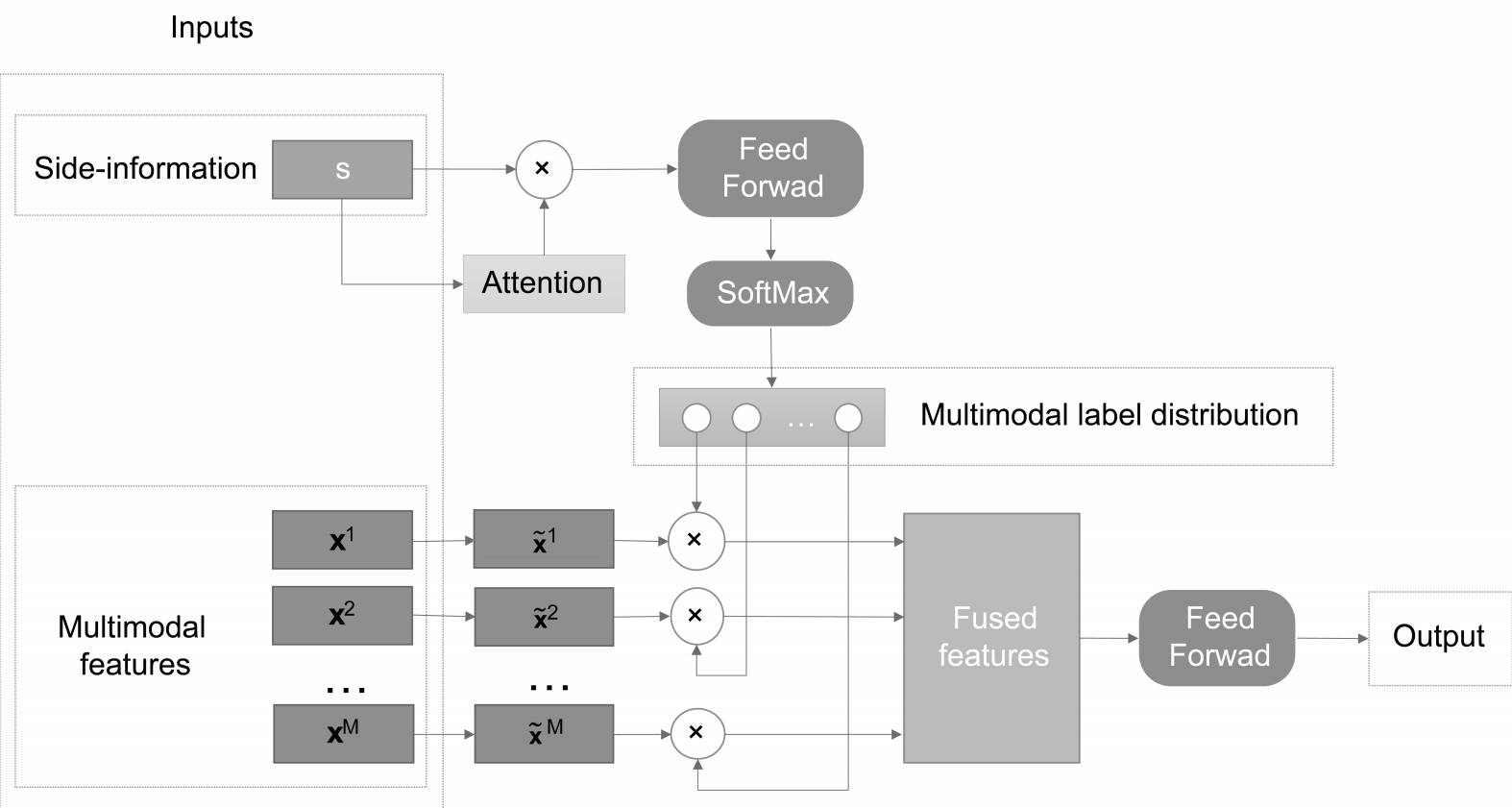
多模态标记分布学习框架如图2所示。定义 为第 个模态的描述度,则多模态标记分布为 。我们假设 ,那么所有模态可以完整描述该示例,即。由于描述度与概率分布具有相同的约束,因此 可以表示为条件概率,。本文构建条件概率函数 来求解:
其中,为模型参数, 为偏置,为隐含层输出,本文设置为两层隐含层:
其中, ,为激活函数,可以为任意非线性函数如tanh或relu等。为了获得更好的理解能力,本文采用了自注意力机制:
其中,,,为参数矩阵。
在对多模态进行融合前,我们采用线性变换将各模态特征映射到同一特征空间:
再用多模态标记分布指导多模态融合:
最后,我们通过前馈神经网络构建多模态融合特征到任务标记的映射:
则多模态标记分布学习的任务为最小化分类交叉熵损失:
时序多模态标记分布学习
对于时序数据,其特征空间为 ,其中表示边信息的时间序列,则表示第 个模态的时间序列。本文根据时序数据特点,提出了先融合多模态标记分布学习和后融合标记分布学习算法。
对于各个模态数据可对齐,且边信息会随时发生改变的时序数据,即,如图1所示的视频数据,本文提出先融合多模态标记分布。首先将边信息与各个模态在时间轴上进行对齐,并根据多模态标记分布学习框架进行融合,然后采用双向LSTM对融合后的时序特征进行学习:
其中,为融合后的时序特征,利用注意力机制进行池化:
则融合后特征到任务标记的映射变为:
而对于各个模态无法对齐,且边信息不会发生改变的时序数据,如多模态疾病预测问题中,我们可以将患者信息作为边信息,而其检查结果作为多模态特征,则在该次就诊时患者信息不会发生改变,且检查结果数据之间不存在对齐,本文提出了后融合多模态标记分布学习。首先采用双向LSTM对时序数据进行特征表达:
其中, 为第个模态的时序数据,同样采用注意力机制进行池化:
则可以替代多模态标记分布学习框架中的 进行多模态融合。
实验
本文将先融合多模态标记分布学习算法应用于情感分析任务,并在CMU-MOSI与CMU-MOSEI数据集上进行实验,与现有先进算法进行比较,展现出了更好的鲁棒性。如图3所示,为部分实验结果,展示了随着环境变化,各个模态重要性发生改变。

本文将后融合多模态标记分布学习算法应用于疾病诊断任务,在MIMIC-III数据集上进行实验。采用Word2vec方法将结构化的患者特征与检查结果进行词嵌入,从而挖掘特征间的潜在联系。该算法与现有先进算法进行比较,表现出更高的准确性与泛化能力。
